Client-side context search
How to serve personalised results without user profiles
“Perfection is achieved, not when there is nothing more to add, but when there is nothing left to take away.”—Antoine de Saint-Exupéry.
While building our search engine and thinking about how best to rank search results, we encountered the question of whether results should be personalised or not. The common belief is that personalised results are great and add value to the user experience, but it comes with some caveats. First, it creates an echo-chamber: once you are inside of your information bubble it is hard to see what is outside of it. And second, personalisation typically brings up privacy concerns, because user information is aggregated on the server-side. The more detailed the user profile is, the better personalisation works.
In our series of blog posts so far, we have sought (and hopefully succeeded) to emphasize our privacy-oriented approach towards building a search engine, and we did not want to compromise on our principles in this case either. Consequently, we started to think about a way of providing personalised results while avoiding the two problems mentioned above. And we had a very simple idea of how to do it, which appears to work out pretty well in production.
In one of our previous posts we talked about our browsers and “search as you type” approach implemented in the dropdown url bar. Building search inside the browser allowed us to use a fat-client approach to do local-processing of client-side data, and to implement “client-side context search” for our dropdown search results. This module[1], which by the way is open-source, has helped us serve personalised results, based on short-term context while maintaining the users’ privacy.
What this module does:
- It is intentionally very simple—as a matter of fact, this was built as a showcase for a recommendation system, which once tested, turned out to work even better than expected.
- It builds a local cache with metadata about visited urls, open tabs and windows on a short time frame. Let us re-emphasize, this local cache, the temporal user profile, never leaves the browser. In most cases it takes into account title and description of the page, as well as some other metadata. This data gets sanitized in order to exclude private pages from the cache. In the end, the cache contains the most popular words from all visited pages with additional meta information, to name a few: on how many distinct pages this word has appeared, how old is the entry, is the page still open or does it come from history, etc.
- With every new url the cache gets updated and old entries are removed after some time. While searching, users usually work on one task at a time, and this task rarely lasts very long. With this approach we were able to create a cache, which represents the current context of the user—what is the user looking for now. While testing we were experimenting with time frames, and it appears that a time window of up to two hours works best. Extending the time window further, let us say 1 day, is in fact detrimental. As multiple different tasks and contexts might collapse into the profile, making it noisier. A clear case of a KISS design[2].
- For each search query we were trying to make an expansion of the query based on data in this local cache. If expansion was successful, the browser fires two calls to the search engine—one with original query, user has entered and another one with expanded query. Results are later combined client-side and presented to the user as final list of urls.
Let us illustrate the gist of the model with an example. You are planning your next summer trip to Malaga in Spain. The default search results for an unfinished query best hotels in Mal produces results for best hotels in Mallorca[3]. But, if the user has searched for information about Malaga in the past couple of hours, we would pick up his current context and expand this query to best hotels in Malaga, providing in this case better personalised results. But once the user switches his context—closes all open tabs about Malaga and starts to search about something else, this information will be deleted from cache after some time and this context will be obsolete.
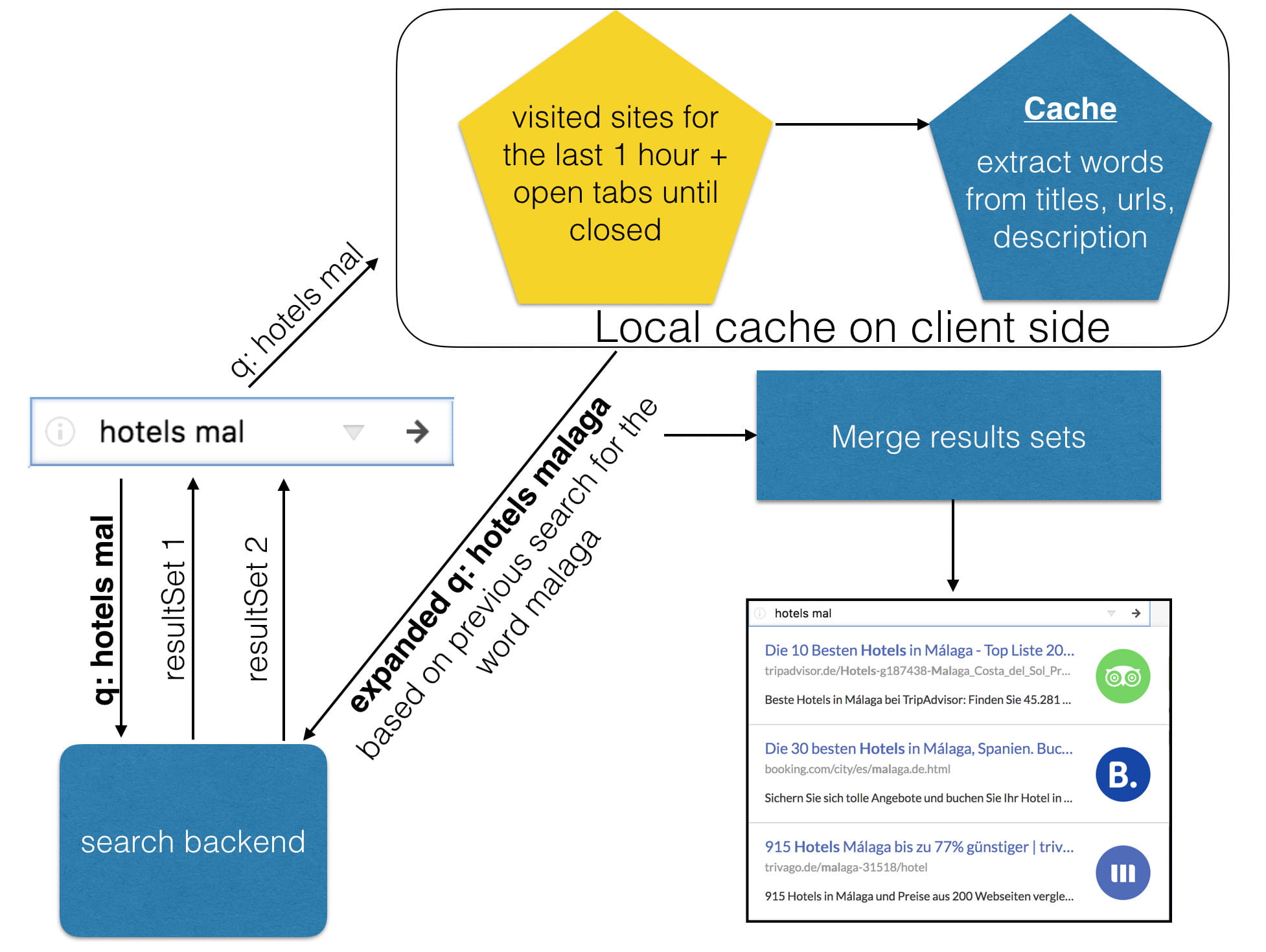
This module works particularly well for unfinished queries, and because almost every query in our dropdown search bar is a partial query, we were able to make a lot of good expansions. Our evaluation shows that personalised expansions trigger about 25% of the time, leading to a 5% increase on engagement. This approach has helped us to give users better results in short-term context while still getting away from creating user profiles and from the echo-chamber that long-term personalisation might bring.
In our current SERP page it is hard to mimic such behaviour, because we have no access to user pages in browser and also we have limited storage (HTML5 localstorage). For example, one option could be to save user’s queries and urls clicked while on the SERP page, trying to use that limited information (title and part of page’s description) we have in our results.
It could be done, but the short-time profile would not be as complete as in the case of the browser. Needless to say that this limitation would not exist if we were tracking users, if privacy is not a concern, you can do this and even more. However, sacrificing privacy for features is something that goes against our policy: we just do not want to do it.