Anti-phishing with privacy in mind
It looks like a dûck, swims like a dūck, but it is not a dück
In previous articles we wrote about how data collection is crucial to build our search engine and some of the browser features (e.g. antitracking). We also described our privacy preserving data collection methodology Human Web. Today we will show you how data can help us fight against phishing attacks, especially those who try to spoof a genuine website so that they can steal passwords or credit card information. We will focus on how we preserve privacy while keeping our users away from phishing websites.
Our anti-phishing system is actually pretty simple. The browser queries it with a prefix of a domain hash and gets a list of suffixes of known phishing domains matching the prefix if there are any. One of the key problems of such an anti-phishing system, or any other anti-phishing system, is to detect the phishing domain fast enough so users will have a minimal exposure to the fraudulent websites. To achieve that, we need to have a way to know the very existence of such domains. Phishing pages are spurious, they usually appear and disappear very quickly without being noticed except by the victims, many attacks last no longer than a few hours.
URLs used for phishing are hard to find, they are hidden and only meant to be discovered by their targets via spam emails, private messages, social networks and forums, etc. Traditional methods to discover web pages on the internet like crawling sitemap.xml are unlikely to discover such pages. The Cliqz browser, as a user agent, has the ability to check all the pages users visit, which makes us the last line of defense against phishing attacks.
How does our anti-phishing system work
First, we need to describe what a phishing page looks like,
- It usually contains login/password forms (to capture the user’s credentials).
- The content must be a very close match to the original website it is trying to impersonate. Otherwise, the users will notice that something is not right.
- Last but not least, the URL has to be somewhat similar to the original URL for the same reason (this is not as critical as the content though). For example who might be hosted on a domain like amazön.com (note the umlaut).
The same things that make the phishing pages look legitimate enough to fool users, are also features that can be used to detect them. We will describe it in a minute.
Discovery
We rely on our users to automatically report any page that is suspected to be a potential phishing page. So, whenever a user opens a page, some checks are performed by the browser, including:
- If the domain of the URL is not in the bloom filter containing the top 500K domains.
- The page content has forms of login to enter credentials or certain keywords.
- The URL passes all Human Web tests, which means it is safe to be sent (privacy-wise) [1].
If these conditions are met, The browser will report the URL as suspicious. Here, we want to emphasize that the URL, because of the Human Web, cannot be traced back to the user who visited the page; no information about the user who sent the URL is communicated to our backend. Here is a sample message:
{
"type": "humanweb",
"action": "suspiciousUrl",
"payload": {
"reason": "password",
"qurl": "https://login.biocklain.info/",
"ctry": "de"
},
"ver": "2.7",
"ts": "20191220",
"anti-duplicates": 261144
}
Once the URL is received by the backend, we will proceed to evaluate whether it is a phishing site or not. We use a simple procedure that leverages our search engine backend. We will get the content of the page, and do a similarity search against the content of the 5 billion pages from our index and known phishing websites (phishing websites are known to reuse similar templates). Then, we can safely evaluate if the page is trying to impersonate a known service (typical targets are payment services, assortment of banks and emails services, etc.). Basically, a phishing site trying to look like Paypal, will have extremely similar content compared to the original paypal.{com|de|...} but the domain will be odd. In addition, certificates can also be used to assess identity.
In case the page is considered fraudulent, any user of Cliqz Browser who visits the same URL will receive an anti-phishing warning on page-load in a matter of seconds.
Assessment
Let us now describe how Cliqz browser protects users from visiting phishing websites. Whenever a user visits a URL, the browser will perform the following checks:
- Domain of the URL is not part of history cache.
- Domain of the URL is not part of the globally known list of popular domains mentioned above
- Domain of the URL is not from the Cliqz search results in the dropdown (otherwise, we would be able to do a time correlation attack to link query and URLs visited. Of course, we have no intention of doing that ever, but it is safer for everyone to just not be able to).
If all these conditions are met, the URL needs to be evaluated against the phishing URLs accumulated at our backend. To be precise, the domain needs to be evaluated (as hijacking legitimate domains is usually hard, it is much easier for the attackers to keep creating new domains).
How to do that privately so no personal information will leak through the backend call? One option would be go through the Human Web, however, to minimize latency, we need a quick scheme which would work even outside the context of Human Web. Therefore, instead of sending the domain to be evaluated, we hashed it with MD5 and send the first 12 bits.
The anti-phishing backend will respond with a list of phishing domains that share those 12 bits. The browser will then evaluate if the visited domain is in the list, locally.
The backend will receive only 12 bits per domain (up to 4096 buckets), it is not possible to determine with any confidence which domain the person was visiting (imagine the potential millions of domains shared across 4096 buckets, way too many collisions).
For example, when user tries to visit paypai.user-security-ref086.com, the MD5 hash of this domain is 8f180c52318cc905995c412db00e9bb7, Cliqz browser queries the backend with prefix of the first 3 hexadecimal characters 8f1.
The response will be like this,
{
"blacklist": [
[
"8bbd0a1d7375aea28412222cec05f",
null
],
[
"5070258b0c6bac1424115c8c4f29e",
null
],
[
"80c52318cc905995c412db00e9bb7",
null
]
],
"whitelist": []
}
We see that 8bbd0a1d7375aea28412222cec05f is part of the blacklist and together with prefix matches MD5 hash of the domain, thus a warning will be shown to the user.
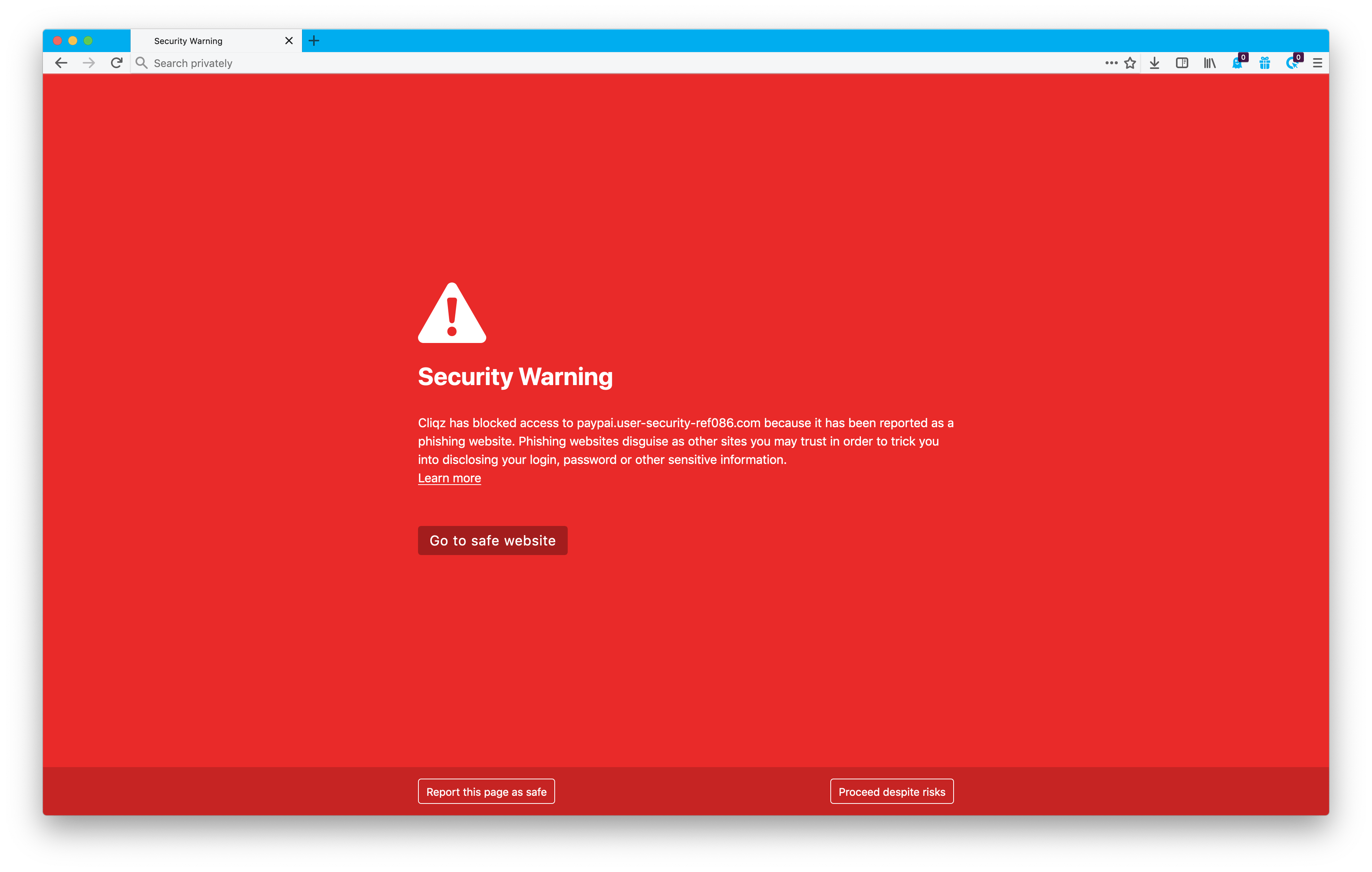
As usual, you do not have to take our word for it, feel free to dig into our source code.
What’s the advantage against Google Safe Browsing
While Google Safe Browsing is good at detecting phishing pages, it was not real-time until very recently (Dec 2019) [2]. Cliqz anti-phishing, on the other hand, was real-time since first deployed in 2016. Real-time is crucial on anti-phishing due to the nature of the attacks. Most of the traffic to the phishing sites occur minutes after the attack is launched (triggered by spam emails, links on social media, etc.) and traffic fades quickly. Even if the phishing page is still available, most of the visits, and damage, are done at the early stages of the attack. People doing phishing attacks do not aim for perfection on the “clones”, rather they value quantity of the attacks over quality.
In Cliqz browser we use both systems as phishing protection: ours and Google Safe Browsing via Firefox. We prefer redundancy on matters of security. Still, we built our own anti-phishing technology, still maintained today, for two reasons. One is that, as much as possible, we aim to remove any dependency on Google. And second, because we wanted to showcase that you can build state-of-the-art services using the data contributed by users while maintaining their privacy.
References
To prevent potential record linkage on data sent to us (Cliqz), URLs that contain hashes, are too long, etc. are discarded. Also, even if the URL is not dropped on the sanity checks, it still has to undergo the Quorum check. The quorum prevents URLs that are only visited by a small subset of people to be sent. Due to this process, we might not be able to learn about URLs that might be phishing sites. This is something that we will need to revisit in the future. However, as of today this is not a crucial problem for now as Cliqz anti-phishing works in conjunction with Google Safe Browsing. If you are curious about the checks and balance on whether a URL can be sent or not, please see the post on Human Web. ↩︎
https://blog.google/products/chrome/better-password-protections ↩︎